Map Interface
Table of Contents
Map Interface Characteristics
In Java, the Map interface is part of the Java Collections Framework and represents a collection of key-value pairs.
Each key in the Map is unique, and it is used to retrieve its corresponding value.
Some key characteristics of the Map interface include:
-
Key-Value Pairs: A Map stores elements as key-value pairs, where each key maps to a specific value.
-
Keys are Unique: Each key in the Map is unique; duplicate keys are not allowed.
-
Fast Retrieval: Given a key, the corresponding value can be quickly retrieved, making it efficient for data lookup.
-
No Specific Order: The elements in a Map are not stored in any specific order, and their arrangement may not match the insertion order.
-
Replace and Update: A Map allows you to replace the value associated with an existing key or add new key-value pairs.
-
Iterable: Though the Map interface itself is not directly iterable, you can obtain collections of keys, values, or entries and iterate through them.
Most Used Map Implementations
Java provides several implementations of the Map interface, each with different characteristics and use cases. Here are the most commonly used Map implementations:
HashMap
- It uses a hash table to store key-value pairs.
- Offers fast access and retrieval time
O(1)for most operations. - Does not guarantee any specific order for keys or values.
- Allows null as both key and value.
Preferred for fast and unordered key-value mapping
Example:
import java.util.HashMap;
import java.util.Map;
public class HashMapDemo {
public static void main(String[] args) {
Map<String, Integer> hashMap = new HashMap<>();
// Adding key-value pairs to the HashMap
hashMap.put("Apple", 1);
hashMap.put("Banana", 2);
hashMap.put("Orange", 3);
hashMap.put("Grapes", 4);
// Accessing the value associated with a key
int value = hashMap.get("Apple");
System.out.println("Value associated with 'Apple': " + value);
// Updating the value associated with a key
hashMap.put("Apple", 10);
System.out.println("Updated value associated with 'Apple': " + hashMap.get("Apple"));
// Size of the HashMap
System.out.println("Size of the HashMap: " + hashMap.size());
// Iterating through the HashMap using entrySet()
System.out.println("Iterating through the HashMap:");
for (Map.Entry<String, Integer> entry : hashMap.entrySet()) {
System.out.println(entry.getKey() + " -> " + entry.getValue());
}
}
}
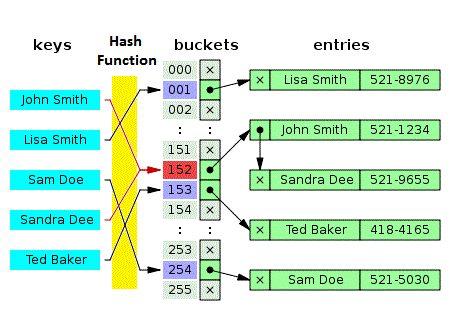
Hashmap internally
Internally, a HashMap in Java is implemented as an array of Node objects (called the hash table) with a linked list or a balanced tree (starting from Java 8) to handle hash collisions. The Node class represents key-value pairs stored in the HashMap
Steps:
-
Hashing the Key: When put a key-value pair into a
HashMap, Java calculates the hash code of the key using thehashCode()method of the key object. The hash code is an integer value that determines the bucket in the hash table where the key-value pair will be stored. -
Index Calculation: To convert the hash code into a valid index in the hash table, Java applies the following computation:
index = hashcode & (table.length - 1). Thetable.lengthrepresents the current size of the hash table, which is usually a power of two. The&operation with(table.length - 1)ensures that the index stays within the valid range of the array. -
Handling Collisions: If two different keys produce the same index after hashing, a collision occurs. To handle collisions, Java uses separate chaining: each bucket in the hash table can hold multiple
Nodeobjects (key-value pairs) forming a linked list or a balanced tree (in case of high collisions). -
Linked List or Balanced Tree: In older versions of Java, collisions are resolved using a linked list. In Java 8 and later, if a bucket’s linked list exceeds a certain threshold (
TREEIFY_THRESHOLD, 8 by default), the linked list is transformed into a balanced tree (red-black tree) to improve lookup time in case of high collisions. -
Performance and Load Factor: The
HashMapmaintains a load factor, which represents the ratio of the number of key-value pairs to the number of buckets in the hash table. When the number of elements exceeds the load factor threshold (LOAD_FACTOR, 0.75 by default), the hash table is resized to accommodate more buckets and reduce the chance of collisions, thereby maintaining performance. -
Resizing: When resizing occurs, the number of buckets (array size) is doubled, and each key-value pair is rehashed to determine its new bucket in the resized hash table. This operation may be expensive, but it ensures that the
HashMapremains efficient even with a large number of elements. -
Iterating through HashMap: Iterating through a
HashMapcan be done using an iterator or by using enhanced for-each loop through theentrySet(),keySet(), orvalues().
Keep in mind that the
HashMapis not thread-safe. If you need a thread-safe version ofHashMap, you can useConcurrentHashMap, which provides better concurrency and performance in multi-threaded environments.
Hash Collision
A hash collision occurs in a hash table or hash-based data structure when two different keys produce the same hash code or index in the underlying data storage. In other words, multiple keys are mapped to the same location in the hash table, even though they should ideally be stored in different locations.
Hash collisions can happen due to various reasons, including:
-
Limited Range of Hash Codes: Most hash functions generate hash codes within a limited range (e.g., 32 or 64 bits). As a result, when you have a large number of possible keys, some of them will inevitably produce the same hash code due to the pigeonhole principle.
-
Low Quality Hash Function: A poor quality hash function may not distribute the keys evenly across the available hash code range, leading to more collisions.
-
Clustering: Over time, hash-based data structures can experience clustering, where keys with similar hash codes tend to cluster together, increasing the likelihood of collisions.
To handle hash collisions, data structures that rely on hashing typically use one of the following techniques:
-
Separate Chaining: In separate chaining, each hash table slot (bucket) contains a linked list or other data structure to hold multiple key-value pairs that have the same hash code. When a collision occurs, new entries are simply added to the list at that slot. This way, multiple keys with the same hash code can coexist in the same bucket.
-
Open Addressing: Open addressing involves searching for alternative locations in the hash table when a collision occurs. Instead of using separate data structures like linked lists, the table itself is utilized to find an open slot for the key-value pair. Various probing techniques (linear probing, quadratic probing, double hashing) are used to find the next available slot in the table.
-
Java’s
HashMapuses separate chaining. When a collision occurs, it stores multiple key-value pairs with the same hash code in a linked list or a balanced tree (after a certain threshold) at the same hash table index (bucket). -
Java’s
HashSetalso uses separate chaining. When two distinct objects have the same hash code, they will be placed in the same bucket in the internal hash table.- See also: Set Interface
- Java’s
HashtableandIdentityHashMapuse open addressing with linear probing for resolving collisions.
TreeMap
- It uses a red-black tree to store key-value pairs.
- Keeps the keys in sorted order, based on their natural ordering or a custom comparator.
- Slower access and retrieval time
O(log n)compared to HashMap.
Suitable when the keys need to be sorted.
Example:
import java.util.Map;
import java.util.TreeMap;
public class TreeMapDemo {
public static void main(String[] args) {
Map<String, Integer> treeMap = new TreeMap<>();
// Adding key-value pairs to the TreeMap
treeMap.put("Apple", 1);
treeMap.put("Banana", 2);
treeMap.put("Orange", 3);
treeMap.put("Grapes", 4);
// Accessing the value associated with a key
int value = treeMap.get("Apple");
System.out.println("Value associated with 'Apple': " + value);
// Updating the value associated with a key
treeMap.put("Apple", 10);
System.out.println("Updated value associated with 'Apple': " + treeMap.get("Apple"));
// Size of the TreeMap
System.out.println("Size of the TreeMap: " + treeMap.size());
// Iterating through the TreeMap using entrySet()
System.out.println("Iterating through the TreeMap:");
for (Map.Entry<String, Integer> entry : treeMap.entrySet()) {
System.out.println(entry.getKey() + " -> " + entry.getValue());
}
}
}
LinkedHashMap
- It uses a hash table along with a linked list to maintain the order of insertion.
- Access and retrieval time similar to HashMap.
- Maintains the order of insertion, offering predictable iteration order.
Useful when you want to preserve the order of keys as they were inserted.
Example:
import java.util.LinkedHashMap;
import java.util.Map;
public class LinkedHashMapDemo {
public static void main(String[] args) {
Map<String, Integer> linkedHashMap = new LinkedHashMap<>();
// Adding key-value pairs to the LinkedHashMap
linkedHashMap.put("Apple", 1);
linkedHashMap.put("Banana", 2);
linkedHashMap.put("Orange", 3);
linkedHashMap.put("Grapes", 4);
// Accessing the value associated with a key
int value = linkedHashMap.get("Apple");
System.out.println("Value associated with 'Apple': " + value);
// Updating the value associated with a key
linkedHashMap.put("Apple", 10);
System.out.println("Updated value associated with 'Apple': " + linkedHashMap.get("Apple"));
// Size of the LinkedHashMap
System.out.println("Size of the LinkedHashMap: " + linkedHashMap.size());
// Iterating through the LinkedHashMap using entrySet()
System.out.println("Iterating through the LinkedHashMap:");
for (Map.Entry<String, Integer> entry : linkedHashMap.entrySet()) {
System.out.println(entry.getKey() + " -> " + entry.getValue());
}
}
}
Choose the appropriate implementation
Choose the appropriate Map implementation based on your specific use case, considering the performance and ordering requirements of your application.
If you need fast operations and don’t care about the order, go with
HashMap.
For sorted elements,
TreeMapis a good choice.
If you need to maintain insertion order,
LinkedHashMapfits the bill.
Comparison Table
| Characteristic | HashMap | TreeMap | LinkedHashMap |
|---|---|---|---|
| Underlying Data Structure | Hash Table | Red-Black Tree | Hash Table |
| Ordering | No ordering | Sorted according to keys | Insertion order |
| Duplicates Allowed | No | No | No |
| Null Elements Allowed | Yes | No | Yes |
| Iteration Performance | O(n) |
O(log n) |
O(n) |
| Use Cases | General-purpose Map | When keys need to be sorted | When order of insertion is important |
Ref.
https://www.geeksforgeeks.org/map-interface-java-examples/?ref=lbp https://docs.oracle.com/javase/8/docs/api/java/util/Map.html
Get Started | Languages | Java Development | Original Collections API | Updated Collections